It's not news that healthcare is expensive. Here is a quick look into what is going on. Why this is going on is a different question that I'll come back to. I looked through World Bank WDI data (link) to visualize three spending areas that get significant attention: - Education expenditures - Healthcare expenditures - Military spending.
This data is limited to the United States from 1995 - 2014. Figures 1 and 2 below show the results.
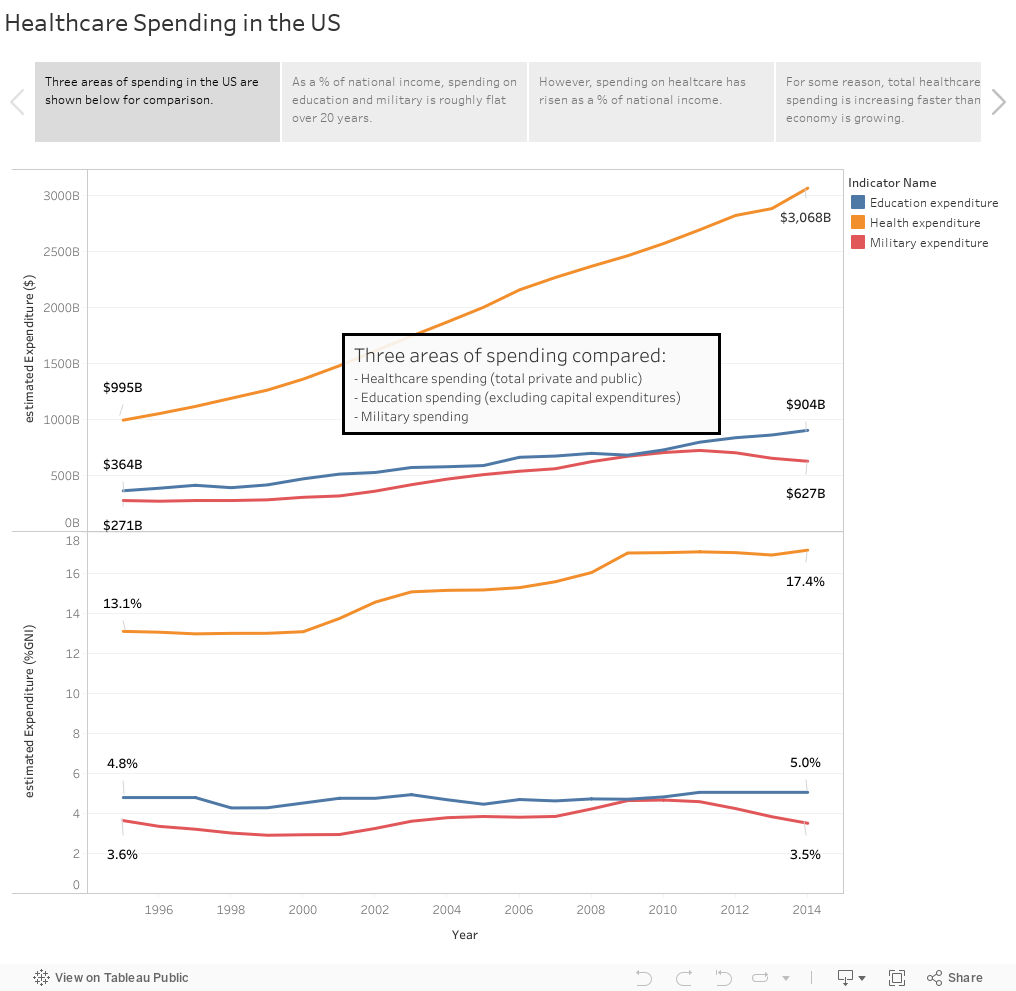
Education and military spending, as a percentage of gross national product (GNI), has remained flat for the last 20 years. Education has remained around 5% and military spending has remaining around 3.5% (with a temporary jump in 2009 to almost 5%). However, healthcare spending has risen as a percentage of GNI over this same time by 4% (from around 13% to over 17%).
Fig 1 - Expenditures as % of GNI (note: for the US, GNI and GDP are very close so I have used the two interchangeably)
When converted to dollars, the increase can be seen more clearly.
Education increases from ~$364 billion to $904 billion
Military increases from ~$271 billion to ~$627 billion
Healthcare increases from ~$995 billion to over $3 trillion
Fig 2- Expenditures in US$
The Centers for Medicare and Medicaid Services maintains a breakdown of healthcare spending (link). The summary of spending (PDF) shows that over 50% goes towards hospital and physician services.
Fig 3 - Breakdown of healthcare spending in the US in 2015
The CMS summary report states that:
Hospital care spending increased by 5.6% in 2015 while prices only increased 0.9%. This means hospital spending was driven by increased usage and intensity of services.
Physician services increased by 6.3% in 2015 while prices declined by 1.1%. This means that physician spending was driven by increased demand.
Taken together this suggests that most of the expenditures are occurring in areas that are being driven up by people needing more or more intensive (and expensive) care.
The interesting next question is: what is driving that increased need or intensity of care and how can those root causes be addressed?
Bonus stuff: A Tableau Public visualization of this data (here).
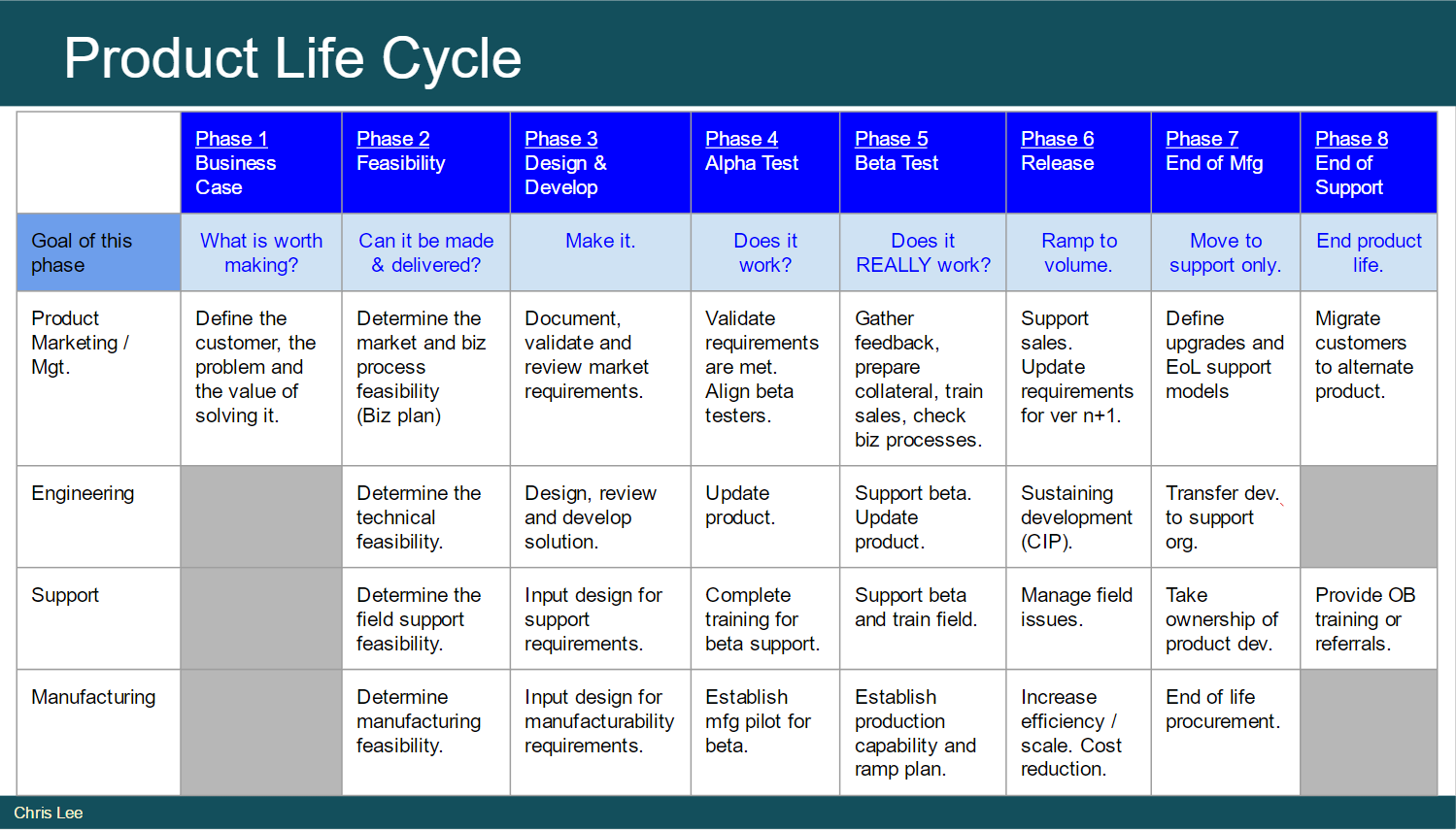
The summary Here is a cheat-sheet for the major steps in a product life cycle (Fig 1). It covers four ideas:
What are the phases in a life cycle?
What is the top level goal of each phase?
Who are the key actors?
What are the actors trying to do in each phase?
But what about agile? Agile is a methodology for answering some of the questions in the life cycle. Agile is not a substitute for a proper life cycle process (more on this in a minute in "cycles repeat"). Choosing whether to follow an agile method or a more traditional waterfall method depends, I have come to believe, on the cost of developing requirements vs the cost of validating those requirements (Fig 2).
Fig 2 - Agile vs Waterfall Development depends on cost.
If the cost of developing your product to a point where the requirements can be tested is LOW, then it pays to adopt an agile approach. Optimize for speed to market because each iteration is cheap.
If the cost of development or testing is HIGH, then it pays to invest more time getting the requirements right before paying to develop and test them. Optimize for learning per unit cost because each iteration is expensive.
The specifics of how much is required to get a testable concept vary from case to case.
For example: The cost of developing and testing a deep UV optical system to determine if it can collect enough data for the detection algorithms to flag a sub-wavelength sized pattern difference is quite high. The cost of testing different parameter entry field orders to determine which one causes more users to follow the correct setup procedure is relatively low. Hence semiconductor capital equipment hardware is not developed according to agile methods while the software that runs the hardware can be developed in an agile way.
Learning at each phase will determine whether to proceed to the next phase or to return to a previous phase (fig 3). I think the most interesting part is that there are basically only two questions here:
Am I solving the right problem?
Is there a better approach to solving the problem at hand?
Under the right conditions, agile is good for moving quickly through the iterations required to answer these questions. However, agile methods, in themselves, won't guide you to ask the right questions at the right time - that is what a product life cycle is for.
Extra stuff:
The slides that these images come from are embedded below.
In a bout of good conversation with a friend, we ended up asking the question:
How do you hold an artificial intelligence (AI) accountable for its actions?
"Punishment!" We said; but... How does one punish an AI? The same way one would punish a person: Take away something that it cares about. What does an AI care about such that taking it away will cause a change in behavior? Why would taking something away cause a change? What would even motivate an AI in the first place? "hmmm...." We said... What if an AI's motivation worked in a completely different way from a human's motivation? What if the AI's value system was built like an insect hive's? Where no member could even conceive of the idea of performing a "bad" (i.e. independent, self-serving, coming at the cost of another) action? Does an ant colony ever have a rogue ant problem? (I think it safe to say that humans have rogue human problems, even without AI.) Perhaps the rogue AI problem comes from the hubristic assumption that a "good" (i.e. functional, effective, general) AI, needs to be modeled on human intelligence? Perhaps, just as a fish doesn't know water, we are blind to our primate sense of fairness and justice, evolved to manage exactly the kind of intelligence we happen to have. Because of this, we can't see an alternative to the idea that a human based intelligence must come with a human based motivational system, including individuality and rule questioning behaviors. Are we, in fact, creating the control problem by assuming that the intelligence we create should function like our own? (Kevin Kelly has something to say about this from a slightly different angle: AI or Alien Intelligence)
I was thinking about Getting Things Done by David Allen and a course I had taken about Outlook best practices. The main idea behind both is this - Get it out of your brain by applying "The 4 Ds:"
Do it now (in less than 2 minutes)
Delegate it to someone else
Defer it (to a date)
Delete it
I have been tweaking how I implement this process over the years and have settled on a process which works for me:
Use email as a buffer to manage messages.
Information from others usually comes in this way. I'll also email myself things that need to be dealt with as they come up.
Deal with the content of the email immediately, delete it or create / edit a task related to the content of the email.
I will usually break down each task into multiple steps required to achieve the desired outcome to the degree possible at the time.
Use the task list as a work queue.
I review the list regularly to understand everything that needs to be done and by when.
I amend the details of each task to use as a record of communications and actions.
Put working blocks into my calendar based on the tasks.
Depending on the task scope and timeline, this means blocking out many chunks across many days.
It ensures that I strike the right balance between standing meetings, appointments and the "real" work... If the balance is off, the calendar will bring that fact forward quickly.
This flow, I realized, is parallel to the flow used to manufacture goods in a factory:
Incoming materials are buffered in trucks and at the dock.
The materials are queued at the appropriate stations in the factory according to what they are used to manufacture.
Processing is scheduled and performed.
The end result is shipped out (or re-queued for a subsequent process).
You don't have a manufacturing line that can't do these things: Buffer, queue, schedule.
Knowledge work is similar: communications are queued into tasks which then must be scheduled and performed.
The problem is that the overhead of working this way is high. It's "easier" to just remember what you heard, what you have to do and then do it.
Up to a point...
When there is too much to do this system breaks.
Email helps because it seamlessly buffers the communications and CAN be used as a task list. Email won't die because a reasonably low friction replacement that does the end-to-end job doesn't exist.
Chat clients don't replace email because email, as it is used at work, isn't about communication. It's about the entire Knowledge workflow.
Make the whole workflow better and you'll kill email (as it is used today).
Though, I suspect, if you make the workflow sufficiently good, you'll find that email is a friend, not an enemy.
I was re-reading Falling Upward by Richard Rohr and got to this quote:
We all try to do what seems like the task that life first hands us: establishing an identity, a home, relationships, friends, community, security, and building a proper platform for our only life. But it takes us much longer to discover “the task within the task,” as I like to call it: what we are really doing when we are doing what we are doing. Two people can have the same job description, and one is holding a subtle or not-so-subtle life energy (eros) in doing his or her job, while another is holding a subtle or not-so-subtle negative energy (thanatos) while doing the exact same job. ...
... In any situation, your taking or giving of energy is what you are actually doing. Everybody can feel, suffer, or enjoy the difference, but few can exactly say what it is that is happening. Why do I feel drawn or repelled? What we all desire and need from one another, of course, is that life energy called eros! It always draws, creates, and connects things.
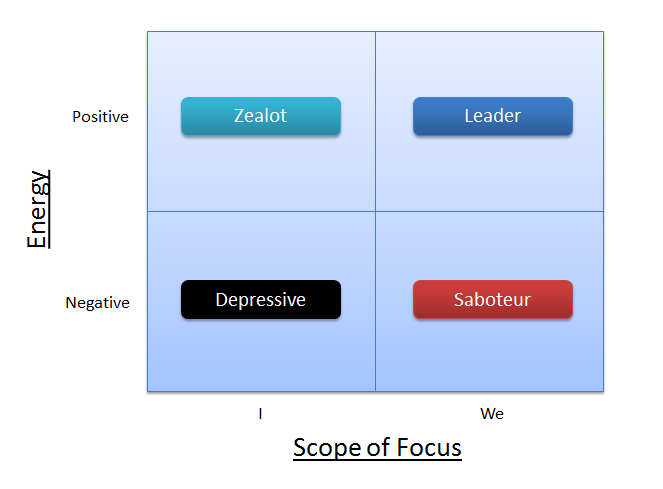
It got me to thinking about my current focus on leading teams at work and the, ah hem, "difficulties" I have had with both myself and others in this space. Thinking for a marketing guy inevitably ends up with a quad chart being produced... so here it is...
Have you met these people?
The depressive energy vampire who manages to get nothing done because of all the "impossible" problems? Though he never takes the team down, he isn't particularly inspiring to be around.
The depressives' opposite, the zealot, who is unshakable and, for better or for worse, is unstoppable? Though he may scout out and create amazing bright spots he can't bring the team along with him.
The saboteur who manages to poison the well with action blocking negativity? This guy is the most dangerous because he does not stop with himself. He's especially dangerous if he is in a position of significant organizational power.
The leader who infuses the right people with the right bits of encouragement when and where they are needed to let the team find its own way to success?
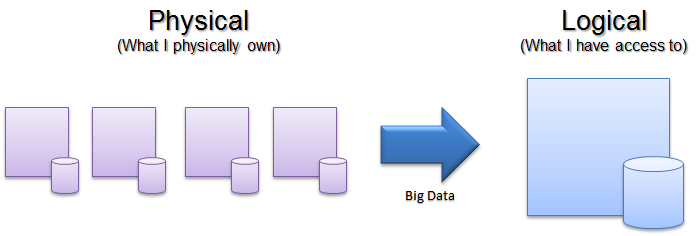
It seems like the term "Big Data" has come to refer to so many things that it has become more of an aspirational marketing term than a technical one.
In dealing with "big data" projects at work I have come to a definition that seems useful.
Big Data is composed of several systems that work together:
The hardware that enables all the other algorithms needed to handle and analyze the data of interest.
The algorithms which efficiently load, transform and store data from varied, high volume data flows.
The algorithms which retrieve and manage the stored data in a way that allows other algorithms and s/w tools to act on it efficiently.
Correlation algorithms which automatically comb through the data looking for data items which are related in ways which might be "interesting" to the end user.
The visualization tools which are used to look at the automatically flagged "interesting" subset of data in order to determine if the data is actually useful and if so, how.
The actionable information that the end user extracts from the system which he uses to further whatever goals originally justified implementing the big data system.
The hardware, ETL and data storage parts have been addressed by a fairly large number of vendors using proprietary and open source methods. You could say that the data handling platform is becoming a commodity because the movement of data is an undifferentiated requirement for all big data users.
What is still hard is algorithmically filtering the flood of incoming data to pull out the nuggets of interest so that someone can confirm their meaning. The aspects which qualify something as interesting differ from industry to industry and company to company so coming up with a common, turn-key solution may not be possible. So, until that statement is proven false, the seller's market for data scientists will continue.
I have been learning a bit about building management systems (BMS) and realized that, abstracted the right way, the manufacturing execution systems (MES) of semiconductor fabs are pretty similar in overall concept and components. That parallel made it much easier for me to frame my learning.
The brains of the system: BMS vs MES.
These s/w systems take schedules, control targets and feedback to make the building "work" (literally).
Granted, building equipment use many more protocols than just BACnet, some of which are proprietary to the equipment vendor.
The building equipment which is actually being controlled for the purpose of making the building useful for its owners.
An office building could be thought of a making an environment conducive to worker productivity with maximum efficiency.
A fab could be thought of as controlling the flow of materials between equipment to maximize output of wafers/chips at minimum cost.
The sensor systems which allow the control system to make smart choices about controlling the building equipment.
For an office building this might mean feedback control for HVAC (don't over cool) and switching off unused lights or dimming lights for daylight harvesting.
For a fab this might mean monitoring the voltage and flow rates for a particular piece of process equipment and adjusting the process recipe for the next lot or wafer to ensure uniform film properties from lot to lot.
More specifically, they each help to reduce the friction between all of the things that must be in place to get something that you want.
International Paper - What does it take to get the paper in your printer?
Rights to log trees. The labor to log them. The tools to cut down a tree. The knowledge to use those tools. The transports to move the trees. The machines to pulp the tree. The labor and knowledge to use the pulping equipment. The chemicals to process the pulp into paper... you get the idea...
United Airlines - What does it take to move yourself to Japan?
The money to buy an airplane. The knowledge to fly it. The contacts required and hours spent to negotiate the rights to take off from SFO and land at NRT. The labor and knowledge to service the aircraft... etc...
Google - What does it take to find out about everything on the internet?
The knowledge to create an algorithm that is helpful at finding what you want amid tons of stuff you don't. The programming skills to implement it. The knowledge to build the IT infrastructure to process and store all of the data required to run the algorithm. The servers and real-estate required to hold the servers... how easy would those be to get on your own?
Facebook - What does it take to find all of your long lost high school friends?
The hours and hours of phone calls to numbers in your old day runner (they still make these?) hoping that their parents still remember you and still live there. Or trawling through phone directories looking for the right Joe Smith... ugh...
OR build your own content site which will attract half of the planet AND get them to list their high school... pretty simple...
The remaining companies or topics flip the equation a bit as they are more general tools for reducing friction towards the end of doing something else.
Twitter - How could I publish my thoughts to "everyone" at a reasonable cost?
I could never mail a letter, call by phone or place enough radio and TV ads to do this. What would it cost to generate the lead list and qualify the leads to do this in a more focused way?
Amazon EC2 - How do I start a s/w business that scales without major capital outlays?
How else can I get enough computers to scale my SaaS business to profitability without the friction of convincing someone to front a significant amount of money to purchase and administer a server farm?
Kickstarter - How do I find funding to raise capital to do something people want to see done?
Am I lucky enough to be born rich? Did I get lucky enough to know powerful, rich people? Am I a good enough social engineer to find these people? Do know the right VCs? Is my product profitable enough to a VC for them to consider? What would it cost to build the audience of millions who are engaged enough to put money on the table - sight unseen?
3D Printing - How do I make a complicated, custom physical part in low volume (qty 1)?
The money and space to buy a CNC machine plus the experience and knowledge to operate it? Or the hours spent to find a machine shop that will do a low volume run, now, for a reasonable price?
Genies - How do I do anything with anyone, anywhere at any time?
You have 3 wishes...
The interesting thing about removing the friction around doing "something else" is that it enables new ways for people to do things for themselves and, ultimately, find others who might want those things. Which they then might trade something for (like money). Which sounds sort of like an economy.
Take that to its logical conclusion where friction is, genie-like, reduced to near zero between all people and the resources / skills they hold and what is the purpose of a corporation as we know it today? We could do anything for ourselves by finding and coordinating the right people.
Maybe this does not happen in my lifetime, but the idea of friction seems like a powerful filter for looking at the value of any product or service that you are trying to create today. If it is not reducing friction then you're heading the wrong way.
After a half day of talking with IBM reps about Big Data products and some use cases, here is how I summarized how the pieces fit together.
At time 0 you collect everything and analyze it for correlations to determine which data items are valuable and how they relate to each other (Big Insights platform). Then you build a control model.
Learning from time 0 is used to configure a "real time" strategy for the data analysis and system control.
Streams provide real time processing of data "on the wire" - nothing need be stored. The output of this is three fold:
"Live" reports for users
A data subset to feed to the data warehouse
Control signals to feed back to the data collectors to adjust behavior (if needed).
Netezza (Data Warehouse) provides a location where "fast" analysis on a "limited" subset of the data can occur.
Hadoop holds everything else so that longer term analysis with full data sets is possible. This could be used to:
Adjust the control models
Change which data subsets are warehoused
Perform ad hoc deep dive analysis.
Perform regular analysis on data sets which are too large to reasonably warehouse (e.g. raw scan data).
Once you have a system which can process huge amounts of data (big data), you need a place to store all of that data. This is what databases are for.
Traditionally, this has meant a relational database. But relational databases place many constraints on how the data is modeled ("normal forms") which are inconsistent with the high volume data sources which need to be analyzed (e.g. all the webpages in the world, all the legal documents in your company or all the tweets being posted each day).
Relational DBs require that data be modeled into a set of tables that contain unique entities (rows), described by attributes (columns) which are arranged in such a way as to describe one aspect of each entity in each table with no redundancies.
said another way:
each row has a primary key made from one or more columns. Column data contains single values (1NF).
All columns in a table relate only to the complete primary key (2NF)
All columns in the table contain data which is not derived from other columns in that table (3NF)
To add more columns which do not fit these constraints, you must put them in another table and join them together.
said yet another way: The key, the whole key and nothing but the key.
These restrictions allow for optimal query structuring and performance while minimizing anomalies due to data changes. However they do not easily support the lack of simple structure between the contents of many data sets.
Non-Relational (NoSQL) DBs remove the restrictions on data normalization and focus, instead, on optimizing around data that does not fit well into the normalized structure which relational DBs (mostly) require. Because there are different analyses of interest and different data sources which "best" embody the data of interest, there are different types of NoSQL databases.
Below is a diagram showing the various database types.
Key Value (aka Big Table)
Data is stored in a GIANT ordered table of rows and columns.
Rows and columns still serve the same general purpose as in a relational DB case
rows = unique entities
columns = attributes.
...but normalization is not required (or expected)...
Data may be sparsely populated in the columns.
I.e. a given row may only have data values for a small fraction of the columns (because most the columns don't apply to the entity this row describes).
Columns may be VERY large in number and depend on what the DB is structured to query for.
e.g. all unique word pairs for the entities in the database
Google originally developed this technology for searching through web pages to fulfill search criteria. Roughly speaking:
rows = web pages
columns = search terms
Document
Entire documents are stored in a searchable format.
Queries search through the documents to identify the information of interest and return statistics or the document IDs.
Good for finding actual documents which contain specific information or summarizing the information contained in a set of documents.
Graph
Stores information about relationships between entities (objects) in the DB
Good for finding objects that are related to each other according to certain criteria.
e.g. find people (entities) who are members of the YMCA (another entity) who lived in New York in 1999.
How does this relate to Big Data?
Many NoSQL DBs are built to operate on distributed file systems and process queries via distributed computing. In fact, the very nature of the data being looked at is so large
NOTE: The MRD should describe WHAT needs to happen overall and between parts. The MRD should not (usually) describe HOW all the parts get implemented - that is for the engineering design document.
Describe the end-to-end scope of the problem to be solved
Break the problem into logical sub-problems
Describe the inputs required to resolve each sub-problem. This includes:
human interfaces for data input
one time
interactive / iterative
machine / data inputs from external data
machine / data inputs from internal (transient) data
Describe what output should be generated by resolving each sub-problem. This includes:
which data is needed as "the" output. i.e. the "permanent" data.
What is the expected input format of the consumer(s)?
which data is needed to address another sub-problem. i.e. transient data.
All of this should be written with an eye to the system in which the functionality described by the MRD lives.
Every input is the output of another system, ideally described by an MRD (reference it if you can).
Other systems may need the output of the system described by your MRD. Include these systems as examples in your MRD to give color to the bigger picture problem being solved.
Human input interfaces (User Interfaces), Machine Input interfaces (APIs) and Permanent Data stores (HDDs or Databases) may be shared between multiple systems. If they are, or should be, note that explicitly.
One obvious challenge, given the recursive approach to MRD writing given here, is figuring out where to stop.
How big should the scope of THE problem be?
My experience: when in doubt, make the scope too big. Then scale back the scope during reviews based on feedback from the stakeholders.
 It's not news that healthcare is expensive. Here is a quick look into what is going on. Why this is going on is a different question that I'll come back to.
It's not news that healthcare is expensive. Here is a quick look into what is going on. Why this is going on is a different question that I'll come back to.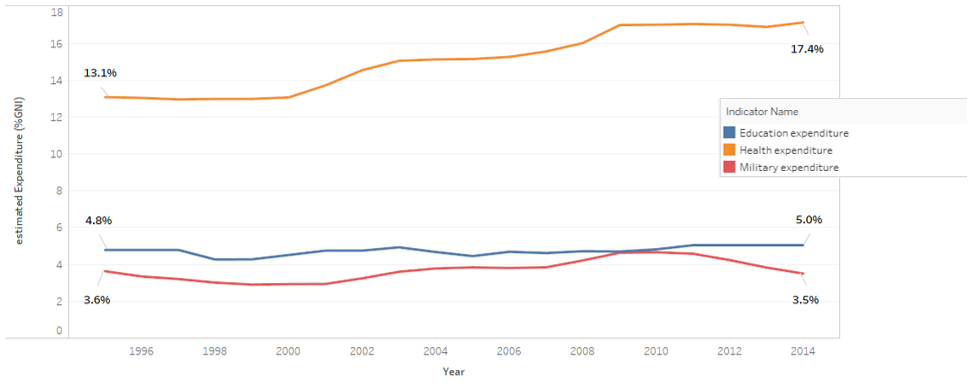













.png)








{kind=link}